-
Async Compute개인 프로젝트 2025. 10. 6. 14:08
개요
이 글에서는 Direct3D 12로 구현된 샘플 프로그램을 통해 Direct3D 12부터 지원하는 Async Compute(이하 비동기 컴퓨트)에 대하여 알아보도록 하겠습니다.
비동기 컴퓨트란?
비동기 컴퓨트가 무엇인지 알아보기 전에 잠시 간략하게 Direct3D 12 API가 GPU에 작업을 제출하는 과정을 살펴봅시다. 대략 다음과 같습니다.
- CPU에서 Command List에 제출하고자 하는 명령을 기록.
- Command List를 Command Queue에 제출.
GPU는 Command Queue에 제출된 작업을 차례대로 꺼내서 실행하게 됩니다. 그런데 Command Queue는 반드시 하나만 있어야 하는 것은 아닙니다. 하나의 프로그램에서 복수의 Command Queue를 생성할 수 있고 각 Command Queue에 제출된 작업은 병렬로 실행될 수 있습니다. 여기서 비동기 컴퓨트가 등장하게 됩니다.
다음은 Direct3D 12의 주요 Command Queue 종류입니다. (모든 종류는 D3D12_COMMAND_LIST_TYPE 열거형을 참조 바랍니다.)
- Copy : 복사(CPU → GPU간, GPU → GPU간 데이터 전송)를 위한 Command Queue
- Compute : 컴퓨팅을 위한 Command Queue
- Direct : GPU에서 실행할 수 있는 모든 명령을 위한 Command Queue
비동기 컴퓨트는 이 중에서 Compute 유형의 Command Queue를 사용해서 컴퓨트 셰이더의 작업을 GPU에서 병렬로 실행하는 것입니다.
Command Queue 생성
먼저 Compute 유형의 Command Queue를 생성하는 코드를 살펴보겠습니다.
D3D12_COMMAND_QUEUE_DESC computeQueueDesc = { .Type = D3D12_COMMAND_LIST_TYPE_COMPUTE, .Priority = D3D12_COMMAND_QUEUE_PRIORITY_NORMAL, .Flags = D3D12_COMMAND_QUEUE_FLAG_NONE, .NodeMask = 0 }; hr = m_device->CreateCommandQueue( &computeQueueDesc, IID_PPV_ARGS( m_computeCommandQueue.GetAddressOf() ) );D3D12_COMMAND_QUEUE_DESC 구조체를 적절하게 초기화하여 CreateCommandQueue 함수를 호출해 Command Queue를 생성하게 됩니다.
D3D12_COMMAND_QUEUE_DESC 구조체의 각 멤버 변수는 다음과 같습니다.
- Type : Command Queue의 유형을 지정합니다. Compute유형의 Command Queue의 경우 D3D12_COMMAND_LIST_TYPE_COMPUTE를 지정합니다.
- Priority : Command Queue의 우선순위입니다. D3D12_COMMAND_QUEUE_PRIORITY 열거형을 사용합니다.
- Flags : 생성 시 사용할 조건으로 대부분은 D3D12_COMMAND_QUEUE_FLAG_NONE입니다.
- NodeMask : 단일 GPU의 경우 무조건 0입니다. 여러 GPU를 명시적으로 사용할 때는 여기를 참고 바랍니다.
그리고 Command List도 Compute 유형으로 생성해야 합니다.
ComPtr<ID3D12CommandAllocator> commandAllocator D3D12Device().CreateCommandAllocator( D3D12_COMMAND_LIST_TYPE_COMPUTE, IID_PPV_ARGS( &commandAllocator ) ); ComPtr<ID3D12GraphicsCommandList> commandList; D3D12Device().CreateCommandList( 0, D3D12_COMMAND_LIST_TYPE_COMPUTE, commandAllocator.Get(), nullptr, IID_PPV_ARGS( &commandList ) );Compute Command Queue를 생성할 때와 동일하게 D3D12_COMMAND_LIST_TYPE_COMPUTE 열거 값을 사용하며 Command Allocator 생성 시 CreateCommandAllocator 함수의 첫 번째 인자로, Command List 생성 시 CreateCommandList 함수의 두 번째 인자로 전달해야 합니다.
기다리기
이제 Compute Command List에 명령을 기록하여 Compute Command Queue에 제출하는 것으로 병렬로 컴퓨트 셰이더를 GPU에서 실행할 수 있습니다. 하지만 이걸로 끝은 아닙니다. 병렬 실행이 있으면 항상 고려해야 하는 동기화 수단에 대해서 파악할 필요가 있습니다. 모던 그래픽스 API로 전환되면서 CPU와 GPU간 동기화가 필수가 된것 같이 비동기 컴퓨트에서는 그래픽스 리소스에 대한 데이터 레이스를 방지하기 위하여 서로 다른 유형의 Command Queue 간의 동기화가 필요합니다. 여기서는 다른 Command Queue의 작업을 기다리는 방법부터 살펴보겠습니다.
CPU ↔ GPU 동기화와 마찬가지로 우선 Fence가 필요합니다. Direct3D 12에서 Fence를 생성하는 코드를 간단하게 소개하겠습니다.
ComPtr<ID3D12Fence> fence; D3D12Device().CreateFence( 0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS( &fence ) );CreateFence 함수의 각 인자를 간단하게 소개하면 다음과 같습니다.
- InitialValue : 초기 값인 부호 없는 64bit 정수입니다.
- Flags : 생성 시 사용할 조건으로 대부분은 D3D12_FENCE_FLAG_NONE입니다.
그리고 Command Queue의 Wait함수를 사용하면 Fence의 값이 지정된 값이 될 때까지 Command Queue의 실행을 기다릴 수 있습니다.
GetComputeCommandQueue().Wait( fence.Get(), fenceValue );다시 Wait 함수의 각 인자를 간단하게 소개하면 다음과 같습니다.
- pFence : 기다릴 Fence 객체 포인터
- Value : 기다릴 Fence 객체의 값
즉 위의 코드는 fence의 값이 fenceValue보다 큰 값이 될 때까지 Command Queue에 쌓인 명령을 실행하지 않도록 하는 대기 명령을 Command Queue에 추가합니다.
신호주기
기다리는 방법을 알았으니, 다음으로 대기를 종료하는 방법에 대해서 알아보겠습니다. 대기를 종료하기 위해서는 Fence의 값이 Wait 함수에서 지정한 값보다 커야 합니다. 즉 Fence의 값을 변경하는 방법을 안다면 대기를 종료할 수 있습니다.
Fence의 값을 변경하는 방법은 다음과 같이 크게 2가지가 있습니다.
- CPU에서 값을 변경
- GPU에서 값을 변경
이중 Command Queue간의 동기화를 위해서는 GPU에서 값을 변경하는 방법을 알아야 합니다. 이 때 Command Queue의 Signal 함수가 사용됩니다.
GetDirectCommandQueue().Signal( fence.Get(), fenceValue );Signal 함수의 각 인자는 Wait 함수와 거의 동일합니다.
- pFence : 값을 변경할 Fence 객체 포인터
- Value : Fence 객체에 설정할 값
위의 코드가 호출되면 fence의 값을 fenceValue로 변경하는 명령이 Command Queue에 추가됩니다.
Wait, Signal 함수는 Command Queue에 직접적으로 명령을 추가하는 방식이기 때문에 알맞은 대기와 신호를 위해서는 미리 실행할 명령을 제출해 놓을 필요가 있습니다. 따라서 다음과 같이 Command List에 기록한 명령을 Command Queue에 제출하고 Wait와 Signal 함수로 Command Queue간 동기화를 수행해야 합니다. 위와 같은 일련의 과정을 구현한 예시 코드인 WaitQueue 함수입니다.
void Direct3D12::WaitQueue( QueueType type ) { /* * Commit함수 내에서 Close() -> ExecuteCommandLists()를 차례로 호출하여 Command Queue로 명령 제출 */ GetCommandList()->Commit(); GetComputeCommandList()->Commit(); if ( type == QueueType::Direct ) { /* * Direct Queue를 기다려야 하는 경우 * Direct Queue에 Signal 함수를 통해 값을 설정하고 해당 값을 Compute Queue가 대기 */ GetDirectCommandQueue().Signal( m_directFence.Get(), m_directFenceValue ); GetComputeCommandQueue().Wait( m_directFence.Get(), m_directFenceValue ); ++m_directFenceValue; } else // QueueType::Compute { GetComputeCommandQueue().Signal( m_computeFence.Get(), m_computeFenceValue ); GetDirectCommandQueue().Wait( m_computeFence.Get(), m_computeFenceValue ); ++m_computeFenceValue; } }제약 사항
Command List 제약 사항
이제 비동기 컴퓨트를 통해서 컴퓨트 셰이더를 병렬로 실행하는 방법과 다른 Command Queue와 동기를 맞추는 방법도 알았습니다. 실제로 비동기 컴퓨트를 사용하기 전에 추가로 고려할 사항이 있는데 바로 제약 사항입니다.
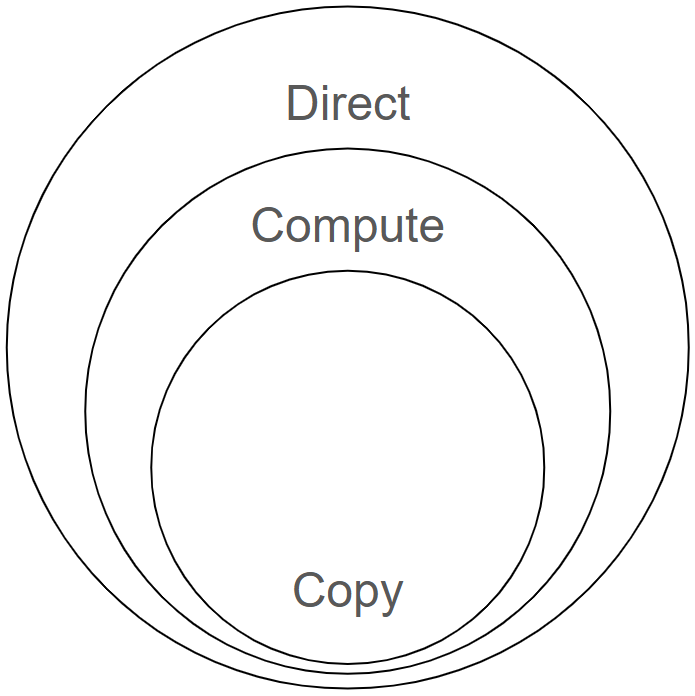
우선 Command List의 제약 사항을 살펴 보겠습니다. Copy, Compute, Direct 이 3가지 유형의 Command List는 모두 ID3D12GraphicsCommandList 인터페이스를 이용하지만, 각 유형 별로 지원하는 함수가 정해져 있습니다. 다음 다이어그램과 같이 Copy → Compute → Direct 순으로 상위 집합을 이루며 상위 유형의 Command List는 하위 유형의 Command List의 함수를 모두 사용할 수 있습니다.
Copy 유형의 Command List가 사용할 수 있는 함수는 다음과 같습니다.
- Close
- CopyBufferRegion
- CopyResource
- CopyTextureRegion
- CopyTiles
- Reset
- ResourceBarrier
Compute 유형의 Command List가 사용할 수 있는 함수는 다음과 같습니다.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState (Compute PSO만 설정 가능)
- SetPredication
- EndQuery
Direct 유형은 모든 함수를 사용할 수 있습니다.
Resource Barrier 제약 사항
두 번째는 Resource Barrier의 제약 사항입니다. ResourceBarrier 함수는 Copy Command List도 사용할 수 있는 함수이지만 Command Queue의 종류에 따라서 전환할 수 있는 리소스 상태에 제약이 있습니다. 따라서 전환 전 리소스 상태와 전환 후 리소스 상태 모두가 해당 Command Queue에서 지원하는 리소스 상태여야 할 필요가 있습니다. Command Queue의 종류에 따라 전환할 수 있는 리소스 상태를 간단하게 나열하면 다음과 같습니다.
Copy 유형에서 전환할 수 있는 리소스 상태는 다음과 같습니다.
- D3D12_RESOURCE_STATE_COMMON
- D3D12_RESOURCE_STATE_COPY_DEST
- D3D12_RESOURCE_STATE_COPY_SOURCE
Compute 유형에서 전환할 수 있는 리소스 상태는 다음과 같습니다.
- D3D12_RESOURCE_STATE_UNORDERED_ACCESS
- D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE
- D3D12_RESOURCE_STATE_INDIRECT_ARGUMENT
Direct 유형에서는 모든 리소스 상태로 전환할 수 있습니다.
예제 프로그램 코드 소개
예제 프로그램에서 비동기 컴퓨트의 주요 구현은 RenderGraph 클래스에 위치해 있습니다. 비동기 컴퓨트로 패스를 실행하고자 할 때 다음과 같이 AddPass의 첫 번째 인자로 비동기 컴퓨트 여부를 전달합니다.
template <ComputePass Lambda> void AddPass( bool isAsync, Lambda&& passBody ) { static_assert( !std::is_same_v<typename LambdaRenderGraphPass<Lambda>::CommandListType, CommandList>, "Graphics command list must need raster output" ); RenderGraphPassType renderGraphPassType = isAsync ? RenderGraphPassType::AsyncCompute : RenderGraphPassType::Compute; AddPassInternal( nullptr, nullptr, nullptr, renderGraphPassType, std::forward<Lambda>( passBody ) ); }이 결과로 RenderGraphPassType::AsyncCompute 유형의 렌더 패스가 렌더 그래프에 추가됩니다. 이렇게 결정된 렌더 패스의 유형에 따라서 다음과 같이 명령을 기록하기 위한 Command List를 선택하게 됩니다.
void RenderGraph::Execute() { Compile(); for ( auto pass : m_passes ) { ExecutePassPrologue( *pass ); /* * 렌더 패스의 유형에 따라 Compute, Direct Command List 선택 */ bool isAsyncComputePass = ( pass->m_type == RenderGraphPassType::AsyncCompute ); auto commandList = isAsyncComputePass ? GetComputeCommandList() : GetCommandList(); pass->Execute( commandList ); ExecutePassEpilogue( *pass ); std::destroy_at( pass ); } CleanUp(); }그리고 렌더 그래프 정렬 과정에서 종속된 패스를 처리하는 과정에서 패스의 Command Queue타입이 다른 경우 동기화를 수행하도록 합니다.
void RenderGraph::SortPasses( const AdjacencyLists& adjacencyLists ) { /* * 중요하지 않은 부분 생략 */ RenderPassList sortedPasses( m_allocator ) while ( queue.empty() == false ) { int32 passIndex = queue.top(); queue.pop(); sortedPasses.emplace_back( m_passes[passIndex] ); for ( int32 i : adjacencyLists[passIndex] ) { --inDegree[i]; if ( inDegree[i] == 0 ) { queue.push( i ); } /* * 패스의 Command Queue 타입을 가져와서 동기화를 수행할 필요가 있는지 체크 */ bool waitForOtherQueue = GetQueueType( m_passes[passIndex]->m_type ) != GetQueueType( m_passes[i]->m_type ); m_passes[i]->m_waitForOtherQueue |= waitForOtherQueue; } } m_passes = std::move( sortedPasses ); }동기화는 RenderGraphPass::ApplyResourceBarrier 함수에서 리소스의 상태를 변경하면서 수행합니다.
void RenderGraphPass::ApplyResourceBarrier() { /* * AddTransition 람다 정의 생략 */ auto AddFencePrologue = [this]() { if ( m_waitForOtherQueue == false ) { return; } if ( m_type != RenderGraphPassType::AsyncCompute ) { /* * Direct인 경우 Compute를 대기 */ GraphicsInterface().WaitQueue( agl::QueueType::Compute ); } }; auto AddFenceEpilogue = [this]() { if ( m_waitForOtherQueue == false ) { return; } if ( m_type == RenderGraphPassType::AsyncCompute ) { /* * Compute인 경우 Direct를 대기 */ GraphicsInterface().WaitQueue( agl::QueueType::Direct ); } }; AddFencePrologue(); AddTransition( m_resourceReads, true ); AddTransition( m_resourceWrites, false ); AddFenceEpilogue(); }비동기 컴퓨트 실행 결과
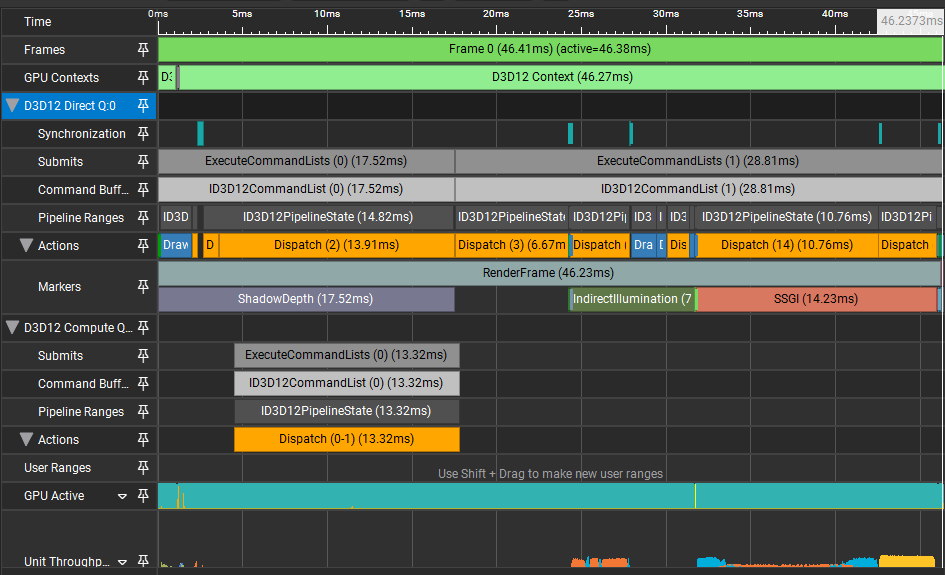
끝으로 예제 프로그램의 비동기 컴퓨트 실행 결과를 PIX Timing Capture로 살펴보겠습니다. GPU Capture의 경우 다음과 같이 GPU 작업이 겹치지 않은 것으로 잘 못 보이기 때문에 Timing Capture를 사용할 필요가 있습니다.

어떠한 리소스 종속성도 없는 GPU 작업에 대해서 Timing Capture를 통해 살펴보면 다음과 같이 Direct Queue와 Compute Queue의 작업이 겹쳐서 실행되고 있는 것을 확인할 수 있습니다.
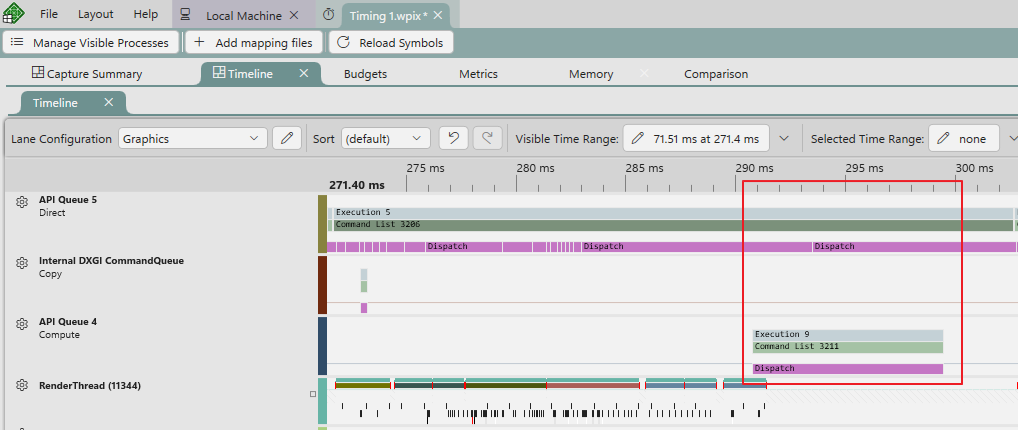
다음으로 리소스 종속성이 있는 GPU 작업을 살펴보겠습니다. Timing Capture를 통해서 보면 다음과 같이 작업이 겹쳐서 실행되고 있는 것을 확인할 수 있으나 제대로 대기가 이뤄지고 있는지는 확인하기 어렵습니다.
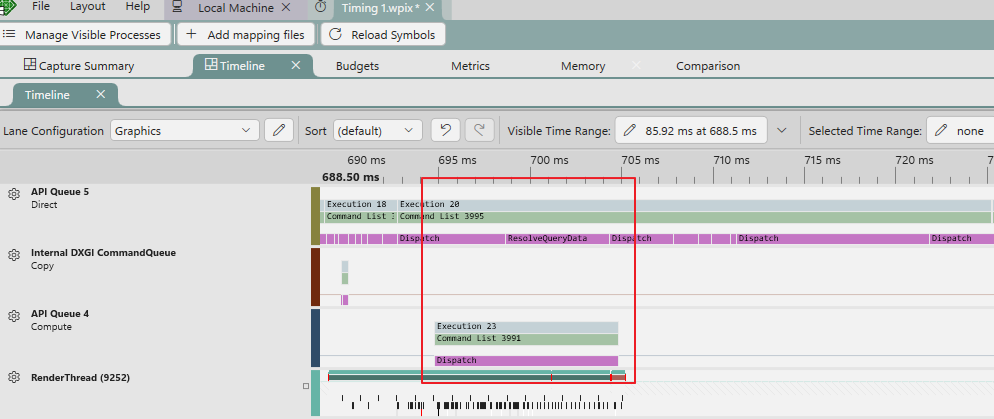
이를 다시 GPU Capture로 확인해 보면 다음과 같이 대기가 적용된 것을 확인할 수 있습니다.

마치며
지금까지 Async Compute에 대하여 알아보았습니다. 마지막으로 예제 프로그램의 Github 링크를 첨부합니다. 세부 코드를 확인하고 싶으신 분은 참고 바랍니다.
연관된 파일은 다음과 같습니다.
- cpp
- Source/RenderCore/Private/Experimental/AsyncCompute.cpp : 비동기 컴퓨트 샘플 렌더 패스 모음
- 셰이더
- Source/Shaders/Private/Experimental/AsyncCompute/CS_HeavyWork.fx : 비동기 컴퓨트 테스트용 더미 셰이더
Reference
'개인 프로젝트' 카테고리의 다른 글
GPU Prefix Sum (0) 2025.11.24 Render Graph (0) 2025.10.17 Screen Space Global Illumination (1) 2025.07.05 PSO Cache (2) 2025.04.26 Mesh Shader (2) 2025.02.25