-
GPU Prefix Sum개인 프로젝트 2025. 11. 24. 16:00
개요
이 글은 개인 프로젝트에서 Visibility Buffer를 구현하는 과정에서 GPU 기반 Prefix Sum을 작성하게 되었고, 이를 별도로 정리해 둘만한 가치가 있는 주제라고 판단하여 작성하게 되었습니다. CPU에서 Prefix Sum을 구하는 직관적인 구현과 달리 GPU에서 병렬로 Prefix Sum을 효율적으로 계산하려면 스레드 그룹 간 동기화 및 데이터 전달 등 여러 요소를 고려해야 하므로 복잡하고 작성해야 할 코드의 양도 비교적 많아 구현 난도가 높습니다.
하지만 이를 구현하는 과정에서 생각할 거리가 많았고 매우 유익한 경험이었습니다. 이 글을 읽으시는 분들도 저와 같은 경험을 얻으셨으면 좋겠습니다.
이제부터 GPU를 이용하여 Prefix Sum을 구하는 방법을 Direct3D 12 컴퓨트 셰이더를 통해서 단계적으로 살펴보겠습니다.
Prefix Sum
알고 계신 분도 있겠지만, 먼저 Prefix Sum이 무엇인지부터 짚고 넘어가려고 합니다. Prefix Sum, Cumulative Sum, Inclusive Scan, 혹은 단순하게 Scan은 배열의 각 요소까지의 누적 합을 의미합니다. 예를 들어 다음과 같은 배열이 있다고 하면
$A = [a_1, a_2, a_3, ..., a_n]$
Prefix sum 배열 $P$는 다음과 같이 정의됩니다.
$P[1] = a_1$
$P[2] = a_1 + a_2$
$...$
$P[n] = a_1 + a_2 + ... + a_n$
배열 $P$의 첫 번째 원소가 $a_1$에서부터 시작하고 있는데 이와 같이 현재 요소를 포함하고 있는 경우를 Inclusive Scan, 현재 요소를 포함하지 않는 경우를 Exclusive Scan 이라고 합니다.
Exclusive Scan 배열 $P$의 예시는 다음과 같습니다.
$P[1] = 0$
$P[2] = a_1$
$...$
$P[n] = a_1 + a_2 + ... + a_{n-1}$
이 글에서 등장하는 예시 코드의 Prefix Sum은 모두 Exclusive Scan이므로 코드를 보실 때 참고하시기 바랍니다.
CPU 기반 Prefix Sum
GPU Prefix Sum으로 들어가기 전에 CPU Prefix Sum 코드를 가볍게 살펴보겠습니다. 다음은 Prefix Sum을 계산하는 C++ 코드입니다.
#include <iostream> #include <numeric> #include <vector> using namespace std; int main() { constexpr int numElement = 10; vector<int> a( numElement ); vector<int> p( numElement, 0 ); // A = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] iota( begin( a ), end( a ), 1 ); // Prefix Sum 계산 부분 for ( int i = 1; i < numElement; ++i ) { p[i] = p[i - 1] + a[i - 1]; } // P = [0, 1, 3, 6, 10, 15, 21, 28, 36, 45] for ( int x : p ) { cout << x << '\\n'; } return 0; }위 코드에서 Prefix Sum의 계산은 하나의 for문으로 매우 간단하게 구현할 수 있습니다. Prefix Sum을 구하기 위해서 n까지 순회가 필요하므로 위 코드의 시간 복잡도를 빅오로 표현하면 $O(n)$이 됩니다.
GPU 기반 Prefix Sum 첫 번째 (Kogge-Stone Scan)
이제 GPU에서 Prefix Sum을 구하는 알고리즘을 살펴보겠습니다. 첫 번째는 가장 단순하고 직관적인 알고리즘인 Kogge-Stone Scan입니다.
Kogge-Stone Scan은 다음과 같은 과정으로 진행됩니다.
- $n$ 개의 요소에 대해서 $log_2n$ 번 다음 과정을 반복합니다.
- 요소의 인덱스 $k$에 대해서 $k\geq2^d$를 만족하면 다음 연산을 수행합니다.
- $A[k]=A[k - 2^{d-1}]+A[k]$
이 알고리즘을 도식화하면 다음과 같습니다.
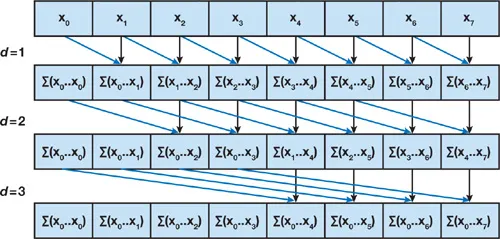
Kogge-Stone Scan의 결과로 Inclusive Scan을 얻게 되고 요소마다 자신을 빼는 것으로 Exclusive Scan을 얻을 수 있습니다.
Kogge-Stone Scan의 시간 복잡도를 빅오로 표현하면 $O(nlogn)$입니다. CPU 기반의 Prefix Sum 코드의 시간 복잡도가 $O(n)$인 것을 떠올려 보면 효율이 떨어지는 방식입니다.
GPU 기반 Prefix Sum 두 번째 (Blelloch Scan)
좀 더 효율적인 GPU 기반의 Prefix Sum 알고리즘을 살펴보겠습니다. Blelloch Scan이라 불리는 이 방식은 크게 Up-Sweep (Reduce) 단계와 Down-Sweep 단계로 구성되어 있습니다.
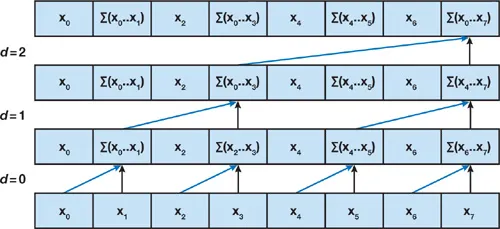
먼저 Up-Sweep 단계입니다.
- $n$ 개의 요소에 대해서 $log_2n$ 번 다음 과정을 반복합니다.
- 요소의 인덱스 $k$에 대해서 현재 깊이를 $d$( 0부터 시작 )라고 할 때 $2^{d+1}$ 간격마다 다음 연산을 수행합니다.
- $A[k+2^{d+1}-1]=A[k+2^d-1]+A[k+2^d+1-1]$
이 단계를 도식화하면 다음과 같습니다.
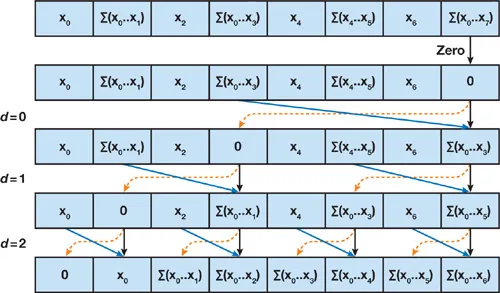
다음은 Down-Sweep 단계입니다.
- $A[n-1]$을 0으로 설정합니다.
- $d=log_2n-1$에서 0까지 반복합니다.
- 요소의 인덱스 $k$에 대해서 $2^{d+1}$ 간격마다 다음 연산을 수행합니다.
- $tmp=A[k+2^d-1]$
- $A[k+2^d-1]=A[k+2^{d+1}-1]$
- $A[k+2^{d+1}-1]=tmp + A[k+2^{d+1}-1]$
이 단계를 도식화하면 다음과 같습니다.
Blelloch Scan은 Kogge-Stone Scan에 비해 거쳐야 하는 단계는 많지만, 시간 복잡도를 따져보면 $O(n)$이기 때문에 훨씬 효율적입니다.
$2 \times (n - 1)$ 번의 더하기 $(n-1)$ 번의 swap
큰 배열에 대한 GPU 기반 Prefix Sum
지금까지 GPU 기반 Prefix Sum을 계산하는 2가지 알고리즘에 대해서 살펴보았습니다. 하지만 아직 한 가지 부족한 부분이 있습니다. 앞에서 살펴본 2가지 알고리즘 모두 큰 배열에 대한 Prefix Sum을 구하기에는 부족하다는 점입니다.
이유는 GPU 메모리의 제약 사항 때문입니다. CPU와 동일하게 GPU 메모리도 여러 단계의 계층 구조를 지닙니다. 이 중 성능을 최대한으로 끌어 올리려면 SM(Streaming Multiprocessor) 내부에 존재하는 온칩 메모리인 Shared Memory를 이용해야 할 필요가 있습니다. 문제는 Shared Memory는 여러 가지 제약 사항이 있다는 점입니다.
- 같은 그룹의 스레드만 접근 가능 ( 접근 범위 제약 )
- Direct3D 11 기준 그룹당 32KB만 사용 가능 ( 메모리 크기 제약 )
따라서 큰 배열은 Shared Memory에 적재할 수 없고 Global Memory에만 담을 수 있습니다. Global Memory의 접근은 Shared Memory에 비해 매우 느리므로 성능에 치명적입니다.
이를 해결하기 위한 아이디어는 간단합니다. 큰 배열을 Shared Memory에 적재할 수 있는 적절한 크기로 나누는 것입니다. 다음과 같은 과정으로 진행됩니다.
- 큰 배열을 적당한 크기의 블럭으로 나눕니다.
- 블럭별로 요소를 Shared Memory에 적재하여 Prefix Sum을 구합니다.
- 그리고 블럭별로 모든 요소의 합을 구해 새로운 배열을 만듭니다.
- 블럭별 합이 담겨있는 배열의 Prefix Sum을 구합니다.
- 2번 과정에서 얻은 Prefix Sum 배열 요소에 4번 과정에서 얻은 Prefix Sum의 결과를 해당하는 블럭마다 더해줍니다.
이를 도식화하면 다음과 같습니다.
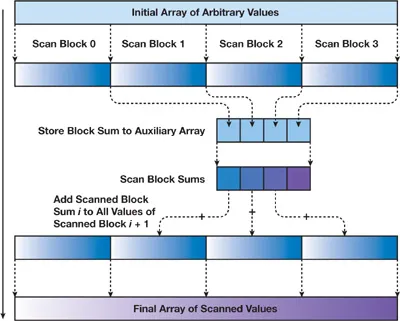
이런 과정을 통해 큰 배열에 대해서도 GPU로 Prefix Sum을 계산할 수 있습니다.
Wave intrinsics를 이용한 GPU Prefix Sum
이제 Direct3D 12 컴퓨트 셰이더로 구현한 GPU Prefix Sum의 코드를 살펴보겠습니다. 그런데 Shader Model 6.0 이상을 지원하는 환경에서는 Prefix Sum을 더욱 간단하게 계산할 수 있는 기능이 제공되기 때문에, 지금까지 알아본 알고리즘을 그대로 사용할 필요는 없습니다.
GPU Prefix Sum을 계산하는 과정이 간단하지 않다는 것만 이해해도 충분하다고 생각됩니다.
지금부터 보여드릴 코드에서는 Wave intrinsics에 포함된 WavePrefixSum 함수를 사용합니다.
WavePrefixSum 함수는 현재 스레드보다 작은 인덱스를 가진 Active Lane의 모든 값의 합을 반환하는 함수입니다. Wave 단위로 동작하는 함수이기 때문에 하드웨어에 따라서 유효한 Lane의 개수가 다른데 NVIDIA 그래픽 카드의 경우 32, AMD 그래픽 카드의 경우 64입니다. 여기서는 32개로 가정하여 설명하겠습니다.
WavePrefixSum이 최대 32개의 Prefix Sum을 계산할 수 있기 때문에 블럭을 Wave 단위로 분할합니다. 이를 도식화하면 다음과 같습니다.
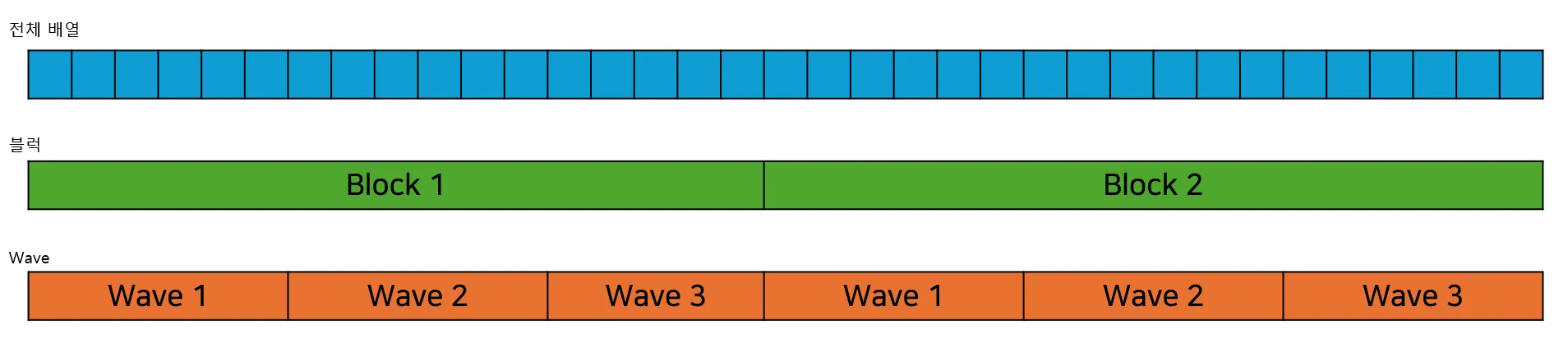
각 Wave의 Prefix Sum을 구하고 이를 취합해 블럭의 Prefix Sum을 구한 다음 다시 이를 취합해서 전체 배열의 Prefix Sum을 구하는 방식입니다.
블럭 Prefix Sum
예제 프로그램은 256개의 요소를 묶어 하나의 블럭으로 취급하고 있습니다. 따라서 하나의 블럭에는 8 그룹의 Wave 그룹이 존재하게 됩니다. 이제 코드를 차례대로 살펴보겠습니다. 먼저 블럭의 Prefix Sum을 구하는 함수인 BlockScan 함수입니다.
#ifndef BlockSize #define BlockSize 256 #endif #ifndef LaneSize #define LaneSize 32 #endif RWStructuredBuffer<uint> Input; uint NumItems; groupshared uint WaveSumPrefixSum[LaneSize]; groupshared uint BlockPrefixSum[BlockSize]; void BlockScan( uint localIndex, uint globalIndex ) { uint value = ( globalIndex < NumItems ) ? Input[globalIndex] : 0; uint laneIndex = WaveGetLaneIndex(); uint waveIndex = localIndex / LaneSize; uint waveSum = WaveActiveSum( value ); if ( laneIndex == 0 ) { WaveSumPrefixSum[waveIndex] = waveSum; } GroupMemoryBarrierWithGroupSync(); if ( waveIndex == 0 ) { uint numWaves = ( BlockSize + LaneSize - 1 ) / LaneSize; uint waveSumToScan = ( laneIndex < numWaves ) ? WaveSumPrefixSum[laneIndex] : 0; WaveSumPrefixSum[laneIndex] = WavePrefixSum( waveSumToScan ); } GroupMemoryBarrierWithGroupSync(); uint wavePrefixSum = WavePrefixSum( value ); BlockPrefixSum[localIndex] = WaveSumPrefixSum[waveIndex] + wavePrefixSum; GroupMemoryBarrierWithGroupSync(); }‘큰 배열에 대한 GPU 기반 Prefix Sum’ 에서 살펴보았듯이 256개의 요소로 이뤄져 있는 블럭의 Prefix Sum을 구하려면 Wave 그룹별 합과 Wave 그룹의 Prefix Sum이 필요합니다.
WaveActiveSum 함수는 매개변수로 전달되는 값의 합을 반환하는 함수로 이를 통해 Wave 그룹별 합을 구할 수 있습니다.
uint value = ( globalIndex < NumItems ) ? Input[globalIndex] : 0; uint laneIndex = WaveGetLaneIndex(); uint waveIndex = localIndex / LaneSize; uint waveSum = WaveActiveSum( value ); if ( laneIndex == 0 ) { WaveSumPrefixSum[waveIndex] = waveSum; } GroupMemoryBarrierWithGroupSync();그리고 그 합을 groupshared 메모리인 WaveSumPrefixSum에 저장합니다. 스레드 그룹의 동기화를 위해서
GroupMemoryBarrierWithGroupSync 함수 호출도 빼놓으면 안됩니다.
다음으로 Wave 그룹의 Prefix Sum을 계산합니다.
if ( waveIndex == 0 ) { uint numWaves = ( BlockSize + LaneSize - 1 ) / LaneSize; uint waveSumToScan = ( laneIndex < numWaves ) ? WaveSumPrefixSum[laneIndex] : 0; WaveSumPrefixSum[laneIndex] = WavePrefixSum( waveSumToScan ); } GroupMemoryBarrierWithGroupSync();WaveSumPrefixSum 값을 WavePrefixSum 함수의 매개변수로 전달하여 Wave 그룹의 Prefix Sum을 계산하고 그 결과를 groupshared 메모리인 WaveSumPrefixSum에 다시 저장합니다.
이제 WaveSumPrefixSum의 계산 결과를 Wave의 Prefix Sum과 합하면 블럭의 Prefix Sum을 얻게 됩니다.
uint wavePrefixSum = WavePrefixSum( value ); BlockPrefixSum[localIndex] = WaveSumPrefixSum[waveIndex] + wavePrefixSum; GroupMemoryBarrierWithGroupSync();전체 배열 Prefix Sum
이제 블럭의 Prefix Sum을 모아서 전체 배열의 Prefix Sum을 계산하도록 하겠습니다. 여기서도 블럭 그룹의 Prefix Sum이 필요한데 여러 패스에 걸쳐 블럭 그룹의 Prefix Sum을 계산하는 대신 현재 패스에서 계산하는 방법을 소개하고자 합니다.
이 방법은 ‘Single-pass Parallel Prefix Scan with Decoupled Look-back’ 이라는 이름으로 NVIDIA에서 2016년도에 소개된 방법입니다.
이를 간략하게 소개하면 스핀락을 이용한 방식으로 자신보다 한 인덱스 전 블럭 그룹까지의 Prefix Sum이 계산되는 것을 스핀락으로 대기하는 방식입니다. 세부 내용은 코드를 통해서 살펴보겠습니다. 전체 코드는 다음과 같습니다.
RWStructuredBuffer<uint> Input; RWStructuredBuffer<uint> BlockId; globallycoherent RWStructuredBuffer<uint2> BlockStatus; RWStructuredBuffer<uint> Output; uint NumItems; groupshared uint BlockIndex; groupshared uint WaveSumPrefixSum[LaneSize]; groupshared uint BlockPrefixSum[BlockSize]; groupshared uint PrefixSum; [numthreads( BlockSize, 1, 1 )] void main( uint GTid : SV_GroupThreadID , uint Gid : SV_GroupID ) { if ( GTid == 0 ) { InterlockedAdd( BlockId[0], 1, BlockIndex ); } GroupMemoryBarrierWithGroupSync(); uint blockIndex = BlockIndex; uint localIndex = GTid; uint globalIndex = blockIndex * BlockSize + localIndex; BlockScan( localIndex, globalIndex ); uint lastIndex = blockIndex * BlockSize + BlockSize - 1; uint back = ( lastIndex < NumItems ) ? Input[lastIndex] : 0; uint blockSum = BlockPrefixSum[BlockSize - 1] + back; if ( localIndex == 0 ) { PrefixSum = 0; if ( blockIndex > 0 ) { uint prevBlockIndex = blockIndex - 1; uint2 status = uint2( 0, 0 ); int i = 0; while ( ( i < MaxSpin ) && ( status = BlockStatus[prevBlockIndex] ).y != 1 ) { i += 1; } PrefixSum = status.x; BlockStatus[blockIndex].x = blockSum + PrefixSum; DeviceMemoryBarrier(); BlockStatus[blockIndex].y = 1; } else { BlockStatus[blockIndex].x = blockSum; DeviceMemoryBarrier(); BlockStatus[blockIndex].y = 1; } } GroupMemoryBarrierWithGroupSync(); if ( globalIndex < NumItems ) { Output[globalIndex] = BlockPrefixSum[localIndex] + PrefixSum; } }BlockScan 함수로 블럭의 Prefix Sum을 계산하고 나면 이를 이용하여 블럭의 모든 요소에 대한 합을 구할 수 있습니다.
uint lastIndex = blockIndex * BlockSize + BlockSize - 1; uint back = ( lastIndex < NumItems ) ? Input[lastIndex] : 0; uint blockSum = BlockPrefixSum[BlockSize - 1] + back;그리고 Decoupled Look-back을 통해 자신의 바로 이전 인덱스 블럭의 Prefix Sum이 계산되는 것을 스핀락으로 대기합니다. 이 부분은 크게 2가지 부분으로 나눌 수 있습니다.
첫 번째로 블럭의 인덱스가 0인 경우입니다. 이때는 기다릴 블럭이 없으므로 블럭의 합을 BlockStatus에 기록하고 Lock 플래그를 1로 설정합니다.
BlockStatus[blockIndex].x = blockSum; DeviceMemoryBarrier(); BlockStatus[blockIndex].y = 1;두 번째는 블럭의 인덱스가 0이 아닌 경우입니다. 이전 블럭의 Lock 플래그가 1이 될 때까지 스핀락을 돌면서 대기하고 이전 블럭의 합이 갱신되면 현재 블럭의 합과 더해 BlockStatus에 기록하고 Lock 플래그를 1로 설정합니다.
if ( blockIndex > 0 ) { uint prevBlockIndex = blockIndex - 1; uint2 status = uint2( 0, 0 ); int i = 0; while ( ( i < MaxSpin ) && ( status = BlockStatus[prevBlockIndex] ).y != 1 ) { i += 1; } PrefixSum = status.x; BlockStatus[blockIndex].x = blockSum + PrefixSum; DeviceMemoryBarrier(); BlockStatus[blockIndex].y = 1; }이를 통해 연쇄적으로 현재 블럭까지의 블럭 그룹의 Prefix Sum을 얻을 수 있습니다. 이제 이렇게 얻은 블럭 그룹의 Prefix Sum을 블럭의 Prefix Sum과 더하는 것으로 전체 배열의 Prefix Sum을 얻을 수 있습니다.
if ( globalIndex < NumItems ) { Output[globalIndex] = BlockPrefixSum[localIndex] + PrefixSum; }이 과정에서 중요한 키워드가 있는데 바로 BlockStatus의 globallycoherent 플래그입니다. BlockStatus는 groupshared 메모리가 아닌 글로벌 메모리에 위치해 있기 때문에 스레드 그룹간에는 메모리 일관성이 보장되지 않습니다. 따라서 Lock 플래그를 통해 다른 스레드 그룹의 작업 완료를 기다려야 하는 Decoupled Look-back에서는 BlockStatus에 globallycoherent 플래그를 붙여줘야 합니다.
마지막으로 구현 중 겪었던 특이사항을 이야기하고 글을 마무리하고자 합니다. 바로 스핀락의 MaxSpin 부분입니다.
int i = 0; while ( ( i < MaxSpin ) && ( status = BlockStatus[prevBlockIndex] ).y != 1 ) { i += 1; }최초 구현에서는 ( i < MaxSpin ) 검사 부분은 없었습니다. 오직 Lock 플래그만 검사할 뿐이었습니다. 문제는 최초 구현에서는 스핀락이 동작하지 않았다는 것입니다. 해당 현상은 제가 가진 장비 중 GTX 1050 그래픽 카드에서 발생하였고 GTX 1650 Ti에서는 발생하지 않았습니다. 이로 미루어 봤을 때 스레드 그룹간 동기화는 그래픽 카드에 따라 다르게 동작할 수 있으므로 상용 코드에서는 다양한 그래픽 카드에 대한 테스트가 필요할 것으로 보입니다.
마치며
제가 준비한 내용은 여기까지입니다. 마지막으로 예제 프로그램의 Github 링크를 첨부합니다. 세부 코드를 확인하고 싶으신 분은 참고 바랍니다.
GitHub - xtozero/SSR at visibility_buffer
연관된 파일은 다음과 같습니다.
- cpp
- Source/RenderCore/Private/Renderer/VisibilityRendering.cpp : Prefix Sum 컴퓨트 셰이더 테스트 코드가 위치. PrefixSumTestBed 함수 참고.
- shader
- Source/Shaders/Private/Visibility/CS_PrefixSum.fx : Prefix Sum 컴퓨트 셰이더.
Reference
'개인 프로젝트' 카테고리의 다른 글
Render Graph (0) 2025.10.17 Async Compute (0) 2025.10.06 Screen Space Global Illumination (1) 2025.07.05 PSO Cache (2) 2025.04.26 Mesh Shader (2) 2025.02.25